논문 주소
https://arxiv.org/pdf/1706.03762.pdf
참고 문헌
https://nlpinkorean.github.io/illustrated-transformer/
코드
https://github.com/tensorflow/tensor2tensor
알아둘 단어
SOTA(State Of The Art) = 현재 최고수준의 신경망
Auto aggressive = 자기 회귀 ~= recurrent 하다
multi-head attention

position-wise feed forward network
- position 마다, 즉 개별 단어마다 적용되기 때문에 position-wise입니다. network는 두 번의 linear transformation과 activation function ReLU로 이루어져 있습니다.
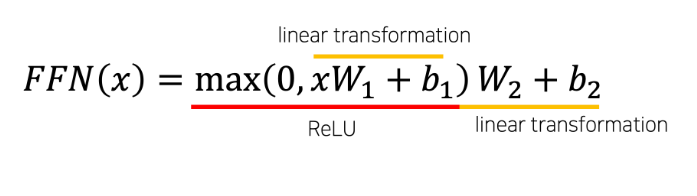
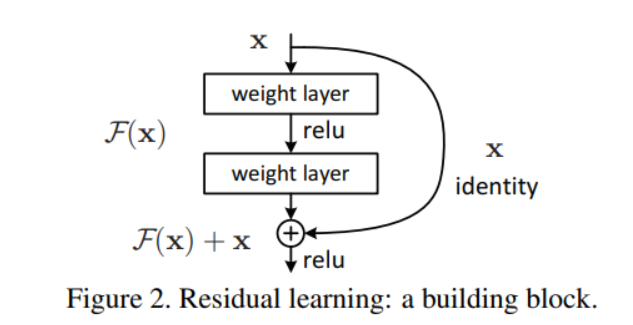
residual connection
- resnet 에서 제안된 residual block의 개념에서 유래했다.
- x + F(x) 의 형태로 비선형 함수의 결과에 기존 인풋을 더해주는 방법이다.
- 처음에는 gredient vanising을 해결하기 위해서 사용되었다. layer의 중간 중간 short cut을 만들어서 depth가 늘어나도 gradient가 잘 통과하면서 문제를 해결하겠다.
- 이는 위의 문제도 해결했지만 skip connection을 하는 과정에서 앙상블(ensemble) 모델을 하는 효과도 가지고 있다.
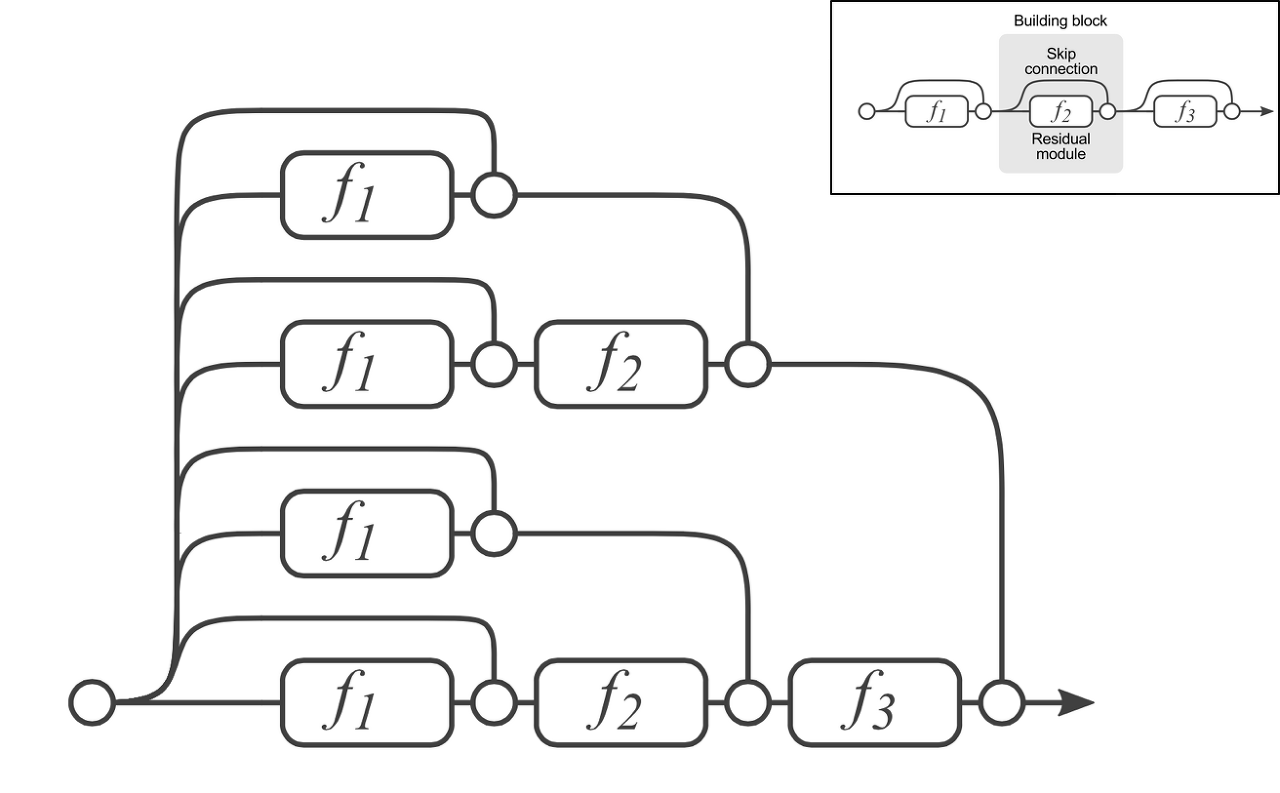
layer normalization
- LN(Layer Normalization)은 inputdml feature들에 대한 평균과 분산을 구해서 batch에 있는 각 input을 정규화한다.
- BN(Batch Normalization)은 각 feature 들의 평균과 분산을 구해서 각 feature 를 정규화 한다.

scaled dot-product attention
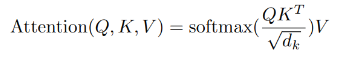

- pytorch
class ScaledDotProductAttention(nn.Module):
def forward(self,Q,K,V,mask=None):
d_K = K.size()[-1] # key dimension
scores = Q.matmul(K.transpose(-2,-1)) # FILL IN HERE
if mask is not None:
scores = scores.masked_fill(mask==0, -1e9)
attention = F.softmax(scores,dim=-1)
out = attention.matmul(V)
return out,attention- self attention & scaled dot product attention 예시 블로그 (https://simpling.tistory.com/3?category=364623)
논문을 읽기 전에 질문.
Q1) RNN이 가지고 있는 문제는 무엇이며 Transformer는 문제들을 어떻게 해소하였는가?
- A1) Long term dependency 문제와 parallization 문제이다.
- transformer는 recurrence를 사용하지 않고 대신 attention mechanism만을 사용해 input과 output의 dependency를 알아내기 때문에 long term depenency 문제를 해결하였다.
- transformer에서는 학습 시 encoder와 decoder에서 각각 parallization 이 가능한 Multi-head attention을 사용하고 이는 각 시점의 정보를 충분히 반영할 수 있다는 장점을 가지고 있다.
- attention은 입력 문장 전체는 행렬로 표현할 수 있고, Key,Value,Query도 모두 행렬로 저장되어 있으니까 모든 단어에 대한 attention 계산은 행렬곱으로 한번에 이루어질 수 있다.
- 반면에 RNN 같은 경우 순차적으로 계산해야 하기 때문에 병렬화가 불가능하다.
- 사실상 self-attention을 사용하기 때문에 위의 문제들을 해결 할 수있다.
Q2) RNN이 recurrent하기 때문에 병렬처리가 불가능 했지만 단어들 사이에 관계를 함의 할 수있었습니다. 그러면 transformer는 어떻게 RNN의 기능을 수행합니까?
- A2) Self-Attention 과 positional encoding을 사용해서 해결한다.
- Self attention은 매번 입력 문장에서 각 단어가 그 문장의 다른 어떤 단어와 연관성이 어떠한지 계산하는 과정이기 때문에 단어사이의 관계성에 집중해서 학습을 진행한다..
- transformer모델은 순차적으로 계산이 이루어지는 CNN이나 RNN을 사용하지 않기 때문에 순서 정보를 따로 넣어준다. 이를 Positional encoding이라고 한다. Positional Encoding 방식은 여러가지가 있지만 논문에서는 사인/코사인 함수를 사용하였다. 이를 통해서 단어들 사이의 거리가 멀 경우에는 PE 값도 커진다.
- 즉, Self-Attention이 주된 기능이고 Positional encoding이 부가적인 역할을 한다.
Q3) self-attention, scaled dot-product attention, multi-head attention, masked multi-head attention을 설명하시오.
- self-attention
- scaled dot-product attention
- multi-head attention
- masked multi-head attention
Q4) decoder에서 masked multi-head attention을 하는 이유는 무엇인가?
- A4) 모델의 목표는 sequential 데이터를 정확히 예측하고자 하기 때문에 전체 정보를 미리 알려주는 것이 아니라 순차적으로 데이터를 제공하며 유추하기를 원하기 때문에 Mask를 사용하여 순서가 되지 않은 데이터의 정보(Attention)를 숨기는 과정을 거친다. 이렇게 Mask를 사용하는 이유는 Input Data가 벡터로 전체 데이터가 한번에 들어가기 때문이다.
- encoder- decoder 구조의 모델들은 순차적으로 input을 받기 때문에 i+1 번째 정보를 고려하지 않지만 transformer는 한번에 값을 받기 때문에 mask를 한다.
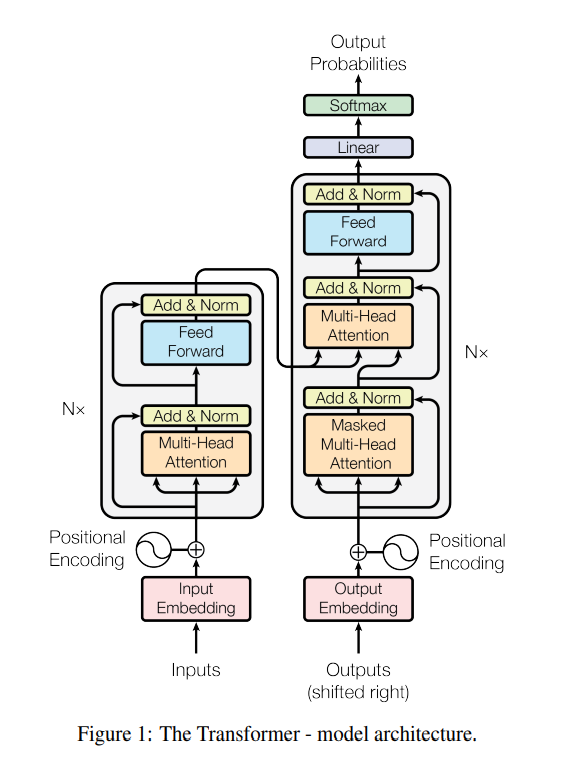
Architecture