6강
Feature Engineering, Feature Embedding
CV(Custom Validation)
Bottom - up
ML Approach (Kaggle View)
1) Search EDA for things that look weird.
2) Verify weirdness by comparing to randomly generated data and confirm that those weird things are in test data
3) Create new features to capture what you see
4) Add to model and tune your model hyperparameters.
5) Confirm CV increases and submit
Top - Down
가설 기반 (Hypothesis-driven)
컨설팅 방법론 (Logical thinking)
가설 – 구현 – 검증 Feature Extraction
1) 데이터에 대한 질문 & 가설
2) 데이터를 시각화하고, 변환하고, 모델링하여 가설에 대한 답을 탐색(구현-성능평가)
3) 찾는 과정에서 배운 것들을 토대로, 다시 가설을 다듬고 또 다른 가설 만들기
가설과 데이터에 의한 추론을 딱 잘라서 구분하기는 어렵지만 개념을 알고있으면 좋을 것 같다.

위는 변수들을 분류하는 예시이다.
숫자형과 범주형 변수에 대해서 말을 하였지만
Continuous, Discrete 변수에 대한 의미를 파악하고 말하는 것이 중요할 것 같다.
나도 모르는 사이에 단어의 의미를 오용하는 경우가 있었던 것 같다. 주의!!
강의에서 제안해주는 FE들
- 시간 데이터가 있다고 무조건 시계열 데이터는 아니다.
- 사용자의 정답률 추이 = 누적 정답률, 최근 정답률 feature를 추가하는 것도 실험해 볼 수 있을 듯 하다.
- 아래는 Continuous Embedding을 사용한 kaggle 솔루션
- https://www.kaggle.com/c/riiid-test-answer-prediction/discussion/210171
- 이전에 풀었던 문항. 시험지가 다시 나오는 경우 -> 과거의 결과를 반영하면 성능 개선이 일어날 수 있을까?
- -> 마스터 클래스에서 이전에 풀었던 문제에서 틀렸던 경우에도 모델에서는 다음에 풀었을 경우에 맞출 것이라고 예측한다고 한다. -> feature importance로 직접적으로 확인해볼 필요가 있을까?? 흠... FE에서 3옵션 정도로 남겨두자.
- 문항, 시험지, 태그의 평균 정답률
- 문항, 시험지, 태그의 등장한 횟수가 정답률과 어느 정도 상관 관계가 있다.
Data Leakage
train, test 데이터가 분리되어 있기 때문에 이를 고려해야한다.
train과 test에서 성능의 차이를 줄이기 위한 방법 중 하나는 역시 데이터를 늘리는 것이다.
다양한 방법으로 고유한 Feature 추출하기
Matrix Factorization
사용자와 사용자가 푼 문항을 통해 user-item 행렬을 만들어줄 수 있다.
-> 실제로 대회에서 제공해준 lightGCN 같은 경우에 테스트 데이터에서 맞춰야 되는 값의 이전 데이터를 사용해서 MF를 만들어준다. => 이렇게 만들어진 MF 를 임베딩 할 수 있는 Feature로 쓸 수 있는 모델과 다른 모델에 어떻게 임베딩해서 적용할 수 있는지 고민해 볼 여지가 있을 것 같다.
유사한 방법으로는 SVD가 있다.단, svd의 단점은 빈공간이 다 차있어야한다. 물론 0으로 fillna를 해주겠지만...
ELO
ELO,IRT를 활용할 수 있다. -> 학생의 잠재능력을 가정하고 학생의 과거 데이터를 토대로 모수를 추론-> 문제의 난이도, 정답률을 보고 이 둘의 관계를 계산해서 정답률을 추론한다.
+) elo 레이팅 : https://www.kaggle.com/code/stevemju/riiid-simple-elo-rating/notebook
나무위키 : https://namu.wiki/w/Elo%20%EB%A0%88%EC%9D%B4%ED%8C%85
아마 학생의 elo 점수를 내서 문제 난이도보고 계산할 수 있도록 하는 feature인 듯하다.
Continuous Embedding
범주형 데이터를 새롭게 feature로 만들어서 사용했는데 이를 가중합으로 만들어서 새로운 feature 를 만들어 줄 수 있다.
-> 시도해 볼만하고 합리적으로 보인다.
대회 1등 솔루션 분석
LGBM,DNN
- 일반적으로 FE을 통해 아주 많은 Feature를 만들어 내야하고, 유의미한 것을 찾기도 어려움
Transformer
- 아주 많은 양의 데이터를 요구로 하고
- Sequence 길이의 제곱에 비례한 시간 복잡도를 가지기 때문에 사용하기에 부담스러운 점이 있다.
Riiid 대회에서도 한 유저가 위 두 가지 문제를 모두 해결한 방법을 통해서 1등을 차지했다.
Last Query Transformer RNN
1. 다수의 feature를 사용 안하고 Sequence를 늘렸다. -> 시간 복잡도가 상승함
2. 마지막 Query만 사용하여 시간 복잡도를 낮췄다.
3. 문제 간 특징을 Transformer로 파악,
일련의 Sequence 사이 특징들을 LSTM을 활용해 뽑아낸 뒤 마디작에 DNN 을 통해 Sequence 별 정답을 예측함
+) 개인적으로는 FE를 transformer로 대체하고, 그 대신 늘어난 시간 복잡도는 마지막 query만 사용하면서 FE에 시간 투자도 안해도 되고, 모델을 돌렸을 때의 시간 소모도 줄이면서 sequence 형태로 데이터를 소모하는 좋은 모델로 보인다.
+) 위 모델을 구현해본 사람이 첨부해둔 Git 주소를 발견하였다. 하지만 이전에 Tabnet 구조를 만들어둔 사람의 git을 참고해서 이식해보려고했지만 실패했던 경험이 있어서 두렵기는 하다. 라이브러리화 되서 제공되는 모델들은 사용하기 쉽지만 이렇게 git으로 구현되어있는 모델들을 활용해서 data에 맞게 돌리는 것은 조금 더 난이도가 높은 듯 보인다.
그래도 한번 보면서 시도해볼만한지 아닌지는 판단해보자.
https://github.com/arshadshk/Last_Query_Transformer_RNN-PyTorc
스페셜 미션 4 FE
우선 가상환경 세팅부터 충돌이 일어났었다.
파이썬 버전 이슈가 있기 때문에 아래와 같은 파이썬 버전을 쓰는 것을 권장한다.
conda create -n mission python=3.6.9
conda activate mission
pip install -q -U PyYAML
pip install -q -U scikit-learn
pip install -q shap eli5 cairosvg jupyter_contrib_nbextensions mglearn pip install category_encoders
pip install gensim==3.8.3
#sudo apt update
#sudo apt install build-essential
# apt update, install은 라이브러리 설치시 gcc 오류가 나는 경우에 실행추가적으로

상황을 마주하게 된다면 gcc 버전을 최신화 하는 것을 추천한다.
sudo apt update
sudo apt install build-essential리눅스 서버에서 진행을 했는데 sudo를 빼고 진행해도 된다.

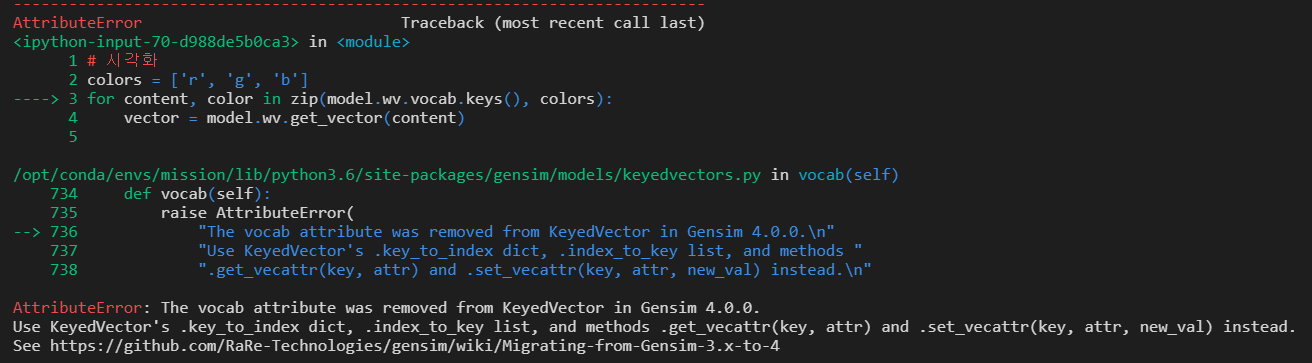
우선 pip install genism을 했을시 4.2.0 버전이 설치 되었다.
하지만 3.8 버전과는 다르게 함수나 여러개가 바뀌어서 에러가 계속해서 난다.
아마도 special mission으로 제공되었던 함수의 recommand.txt가 있었다면 더 쉽게 했을 텐데 아쉬울 따름...
pip install gensim==3.8.3genism을 설치할 때 3.8 버전으로 설치를 하자
이제 환경설정을 완료하였으므로 과제 내용 학습 시작
FE 대분류
- 도메인 지식 (Domain Knowledge)
- 메모리 (Memory)
- 통계량 (Statistics)
- 날짜와 시간 (Datetime)
- 이산화 (Binning)
- 상호작용 (Interaction)
- 행렬 분해 (Matrix Factorization)
- 차원 축소 (Dimension Reduction)
- 임베딩 (Embedding)
- 외부 데이터 활용 (Data Enrichment)
눈에 띄었던 추천 feature
- 앞으로 풀 문제에 대한 누적합(미래 정보)
- 이전까지 풀었던 문제에 대한 누적합(과거 정보)
- 과거 평균 정답률
- 과거 해당 문제 평균 정답률
- 최근 3개 문제 평균 문제 풀이 시간
- 문제 풀이에 사용한 시간을 중간값 기준 +.-,.0 으로 나누어서 얼마나 걸렸는지
알고리즘 문제 풀이
- 문제 링크 : https://www.acmicpc.net/problem/2839
- 개인 깃허브 알고리즘 코드 링크 https://github.com/SeongJaeBae/algorithm
내 풀이
def main():
s = int(input())
#3 5
m_3 = int(s/3)
l_3 = s%3
m_5 = int(s/5)
l_5 = s%5
answer = 99999
#
if l_5 ==0:
return print(m_5)
else:
for i in range(0,m_5+1):
for j in range(0,m_3+1):
if i*5 + j*3 > s:
break
if i*5 + j*3 == s:
answer = min(answer, i+j)
if answer == 99999:
return print("-1")
else:
return print(answer)그냥 빡구현 어거지로 풀었다.
그래서 모범적인 풀이는 무엇일지 검색해보았다.
sugar = int(input())
bag = 0
while sugar >= 0 :
if sugar % 5 == 0 : # 5의 배수이면
bag += (sugar // 5) # 5로 나눈 몫을 구해야 정수가 됨
print(bag)
break
sugar -= 3
bag += 1 # 5의 배수가 될 때까지 설탕-3, 봉지+1
else :
print(-1)
while ~ else 조건문을 사용해서 break에 걸려서 나가지 않으면 자동적으로 -1을 출력해준다.
내가 짠 코드는 거의 완전 탐색에 가까운 방식이어서 시간 복잡도가 조금이라도 타이트했으면 바로 오류가 났을 것 같다.
오늘의 회고
오늘로 DKT 대회 4일차이자 LG AI Ground를 본격적으로 시작한 첫날이다.
DKT 대회에서 주어진 베이스라인 코드들을 기억해두고 나중에 적용할 수 있을 만큼 학습하는 것이 dkt에서의 또하나의 목표라고 생각이든다. 부스트캠프 과정에서 얻을 수 있는 가장 대표적인 교육 과정이며 가져가야 할 것이다.
매일매일 알고리즘 문제를 1문제씩 푸는 것은 계속해서 이어나가야할 생활 습관이라고 생각이 든다. 이제 겨우 3일 정도 된 것 같은데 간단하게 문제를 푸는 정도라면 스트레스도 풀리고, 내가 성장하고 있나 하는 불안감 해소에도 도움이 된다.
AI ground 팀과 첫 미팅을 하면서 느낀 점은 목표를 향해 나아갈 때는 동료와 함께 달려가는 것이 좋다는 점이다. 무엇보다 서로 의견을 교류하면서 동기부여도 되고, 같이 하고 있는 팀에대한 책임감으로 task에 대한 집중도가 올라가는 것을 느낀다. DKT, book rating에서도 EDA를 진득하게 해본 적은 없는 것 같다. DKT를 하면서 어느정도 eda를 해보았지만 특정 column을 분석하면서 아이디어를 얻은 후 top-down으로 FE를 해본 것이기 때문에 이번에는 bottom-up 을 할 수 있을 정도로 EDA를 진행해보자.
부스트캠프를 진행하면서 너무나 좋은 사람들을 너무 많이 만나고있다. 그런데 주변 사람들이 이 힘든 과정 속에서 힘들어하는 모습들이 보이고 있다. 동료들이 힘들어할 때 웃음을 줄 수 있는 사람이 되자. 다들 이렇게 힘들어하고만 있기에는 너무나 뛰어난 사람들이기 때문에 내가 할 수 있는 최선을 다하며 주변에 에너지를 주는 사람이 되자. 지금 이 과정이 육체적으로는 힘들 수 있지만 언제나 말하듯이 내가 할 수있는 최선의 방법은 너무나도 간단하다. 나 스스로는 최선을 다하며, 주변의 사람들에게 먼저 인사하며 잠시라도 웃을 수 있게 열심히 하자.
'부스트캠프 4기 RecSys' 카테고리의 다른 글
| [부스트캠프]DKT 6일차 (0) | 2022.11.22 |
|---|---|
| [부스트캠프] 9주차 회고 , DKT 5일차 (2) | 2022.11.18 |
| [부스트캠프] DKT 3일차 (2) | 2022.11.17 |
| [부스트캠프] DKT 2일차 (0) | 2022.11.16 |
| [부스트캠프] DKT 1일차 (0) | 2022.11.14 |