GKT
관련 블로그
그래프 활용한 노드 간 관계 분석기술로 고도화된 지식추적모델 GKT(Graph-Based Knowledge Tracing)
By 김정훈
medium.com
max_sequence list 최근 거로 제한 걸어서 batch 내 memory 소모 줄이기 -> uesr 마다 memory 사용 감소로 더 빠르게 학습 and 더 큰 batch 사이즈 학습 가능 + train set validation set을 합치고 마지막 거만 validation으로 넘겨서 모든 데이터를 학습에 활용 -> 기존에 돌렸던 log 와 비교해야 할 듯
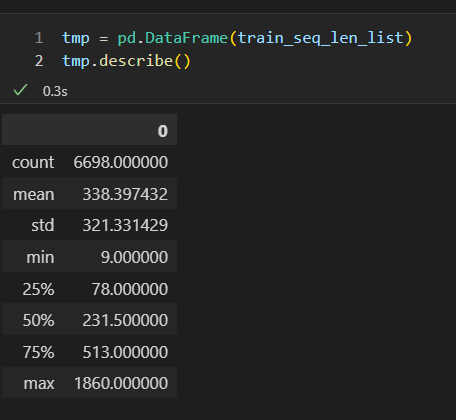
그래프 모델에서 존재하는 max_sequencelist의 분포값을 확인했다. 어느 정도를 max로 생각해두고 상위 25퍼센트 or 600 선에서 정리해야 할 듯하다. 메모리가 너무 많이 들어서 batch size를 크게 하지 못하는현상이 맘에 안들어서 바꿔야할 듯
현재 batch size와 max_seq_len을 조절하여 1 epoch에 1시간 정도로 세팅을 해두었다.
오늘 15 epoch 정도로 돌려보고 상황을 체크해봐야 할 듯 하다.
+) 현재 이 모델은 predict를 진행할 때 해당하는 user의 문제가 3개 이상이어야 제대로 predict 결과값을 알려준다.
따라서 마지막 3개 값 정도를 추출해서 사용하였는데 이렇게 사용하는 것과 user를 random split 해서 유저의 전체 데이커 sequence를 넣었을 때와의 차이점도 확인해야 할 필요가 있어보인다.
리더보드와 validation 스코어를 세심하게 체크하면서 모델 실험을 진행해야 할 듯 하다.
+) 이렇게 커스텀을 할 수 있도록 선발대로서 많은 역할을 해준 승훈이와 재형이에게 박수를 치고 싶다
Tmux
터미널을 켜두고 있지 않더라도 모델이 학습할 수 있도록 tmux를 사용해서 모델을 돌렸다.
tmux 세션 시작
$ tmux new -s [세션명]
현재 돌아가고 있는 세션 확인
$ tmux ls
실행중인 세션명을 통해서 접근 할 수 있다.
$ tmux attach -t [세션명]
출처 : TMUX 사용법
Tmux 사용법 - 중단없이 딥러닝 학습하는 방법 · ML감자
Tmux
pebpung.github.io
오늘의 회고
GKT 실험 세팅을 하기위해서 2일 정도 걸렸던 것 같다.
CV,NLP 에서 사용하는 모델처럼 무겁다 보니깐 내가 원하는 양식으로 돌리기 위해서 체크하는 과정에서 시간이 불타서 사라졌다. 다행히도 원하는대로 돌릴 수 있게되어서 결과를 확인 할 수 있어서 다행이다.
중간 중간에 변성윤 마스터님께서 추천해주었던
'출근했더니 스크럼 마스터가 된 건에 관하여' 책을 읽었다. 전에 '함께 자라기' 를 읽으며 협업에 대해서 고민했던 것보다 디테일하게 스크럼 이론에 대해서 알려주어서 흥미롭게 보고있다. 보고 난 후 스크럼에대해서 정리를 해두어서 향후 부캠 최종 프로젝트에 적용해서 PM과 비슷한 스크럼 마스터 역할도 경험해 보면 좋을 것 같다.
서버가 돌아가는 동안에는 lightGCN 모델을 보면서 기존에 제공된 baseline graph 기반 모델은 어떻게 돌아가는지 확인해보고자 한다.
+) 각자 돌아가면서 모델을 학습하다보니 내가 했던 부분에 이어서 개발하는 캠퍼도 있고, 다른 캠퍼가 진행했던 진행사항에 내가 추가로 개발을 하기도 하는 경험이 신선하고 재미있어서 다행인 것 같다.
애자일 개발이 처음인 내가 출근했더니 스크럼 마스터가 된 건에 관하여
싸니까 믿으니까 인터파크도서
생년월일 1975 저자 신상재는 일본 기술서 번역가이자 ‘번역하는 개발자’ 유튜버다. 삼성SDS에서 소프트웨어 아키텍트로 활동하다가 애자일 코어 팀 ACT에 합류하였다. 기술보다는 사람이라는
book.interpark.com
'부스트캠프 4기 RecSys' 카테고리의 다른 글
| [부스트캠프 4기] Movie Recommendation 대회 후기 (0) | 2022.12.27 |
|---|---|
| [부스트캠프] DKT 대회 회고 (0) | 2022.12.13 |
| [부스트캠프] DKT 7,8일차, AI ground (0) | 2022.11.23 |
| [부스트캠프]DKT 6일차 (0) | 2022.11.22 |
| [부스트캠프] 9주차 회고 , DKT 5일차 (2) | 2022.11.18 |