Tracked File이란?
-
- Unmodified/Modifed/Stage일 경우: 이 파일이 Git에 의해 관리가 되고 있다.
- Untracked일 경우: 이 파일은 Git에 의해 관리가 안되고 있다. (= 방금 추가한 파일이거나 쓸모없는 파일임을 추측 가능)
- Modified일 경우: 이 파일은 변경되었다. 변경되었다고 기록을 해야 한다.
- Unmodified일 경우: 이 파일은 저번에 저장한 파일과 비교해보니 그대로이다.Git이 관리해주는 파일(Tracked File)은 다시 한번 더 파일의 상태를 3개의 상태로 세분화해서 관리합니다.
- Unmodified: 파일이 수정되지 않은 상태 (= 파일이 최근에 저장한 상태 그대로임)
- Modified: 파일이 수정된 상태 (= 파일이 최근에 저장한 파일과 달라짐)
- Staged: 파일을 저장할 예정인 상태 (= 이 파일을 저장할 것이라는 뜻)
Untracked File이란?
Untracked File은 이 파일이 Git 저장소에는 있지만 Git에 의해서 관리되고 있지 않은 파일입니다. Unmodified/Modifed/Stage이 세 가지 외의 상태는 모두 Untracked입니다. Untracked File은 삭제되든 변형이 일어나든 Git이 추적하고 있지 않기 때문에 손상되었을 때 Git으로 복구할 수 없습니다.
Git이 파일을 분류하는 방법에 대해서 알아봤습니다. 우리가 Git으로 관리되는 폴더에 넣어준 모든 파일은 이렇게 관리가 됩니다. 이제 이러한 Git이 분류해주는 파일의 상태를 확인하는 명령어를 배워봅시다.
add를 통해서 untracked 상태에서 벗어날 수 있다.
git commit -a -m “commit_name”
-a 는 auto adding이다. 하나하나 파일들을 add 하기 귀찮을 때 사용
이렇게 할 때 untracked된 파일은 commit 되지 않는다.
한번이라도 add를 한 tracked 된 파일에 대해서만 auto adding이 된다.
= git commit -am “commit_name”
add의 의미
- commit 대기 상태를 만든다.
- untracked를 tracked로 만든다
.gitignore
password나 오픈하면 안되는 정보들을 이 파일에 목록들을 저장해둔다.
여기에 들어가있는 곳은 기록된 파일들은 없는셈친다.
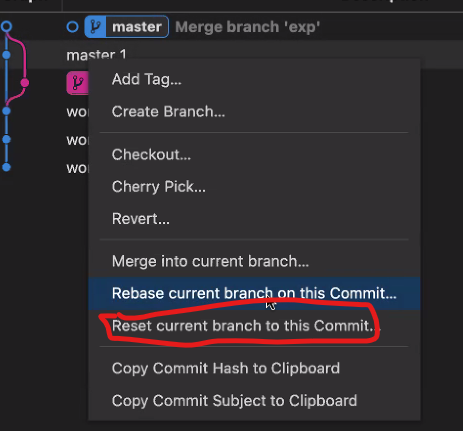
checkout은 head를 옮기고, reset은 head가 가리키는 branch를 옮긴다.
- git reset —hard이전에 했던 commit으로 checkout하는 것과의 차이점은?취소를 한다고 하더라도 git은 삭제하지 않기 때문에 git reflog를 사용해서 삭제된 과거의 commit의 id로 갈 수 도 있다.
if(attached){
HEAD의 Branch가 움직임
} else {
== checkout
}
- HEAD의 Branch가 움직임
- git reset --hard COMMIT_ID로 Branch를 이동
- check out은 시간여행이지 최근 작업물의 커밋을 지우지는 못한다.
- 이 명령어를 사용해서 뒤의 주소로 이동하면서 commit을 취소할 수 있다.
branch를 만드는 것이 버리기 쉽기 때문에 branch 를 만드는게 유리하다.
git log —oneline -all -graph
⇒ git graph 없이도 git bash 창에서 그래프로 표현해줌
'부스트캠프 4기 RecSys' 카테고리의 다른 글
| [부스트캠프] 5주차 회고 (0) | 2022.10.21 |
|---|---|
| [부스트캠프] Github 특강 3회차 (0) | 2022.10.21 |
| [부스트캠프] 4주차 회고 (0) | 2022.10.14 |
| [부스트캠프] Github 특강 1회차 (1) | 2022.10.12 |
| [부스트캠프] 3주차 회고 (0) | 2022.10.07 |