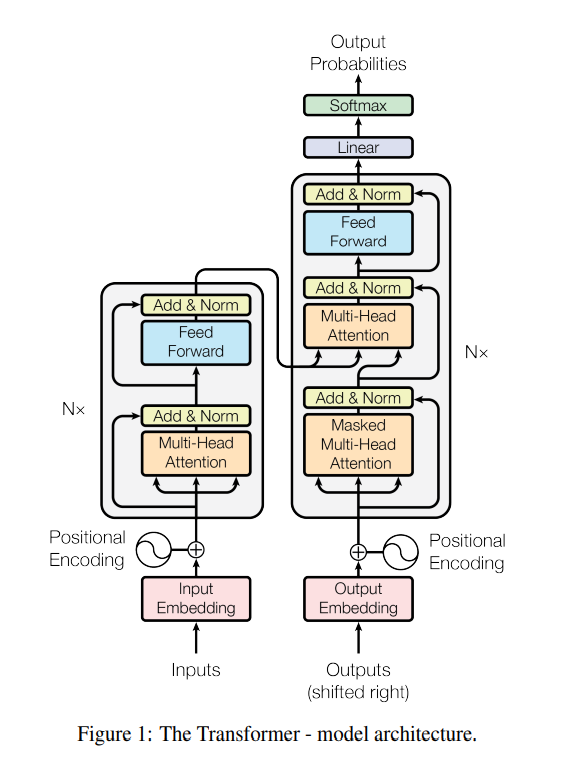
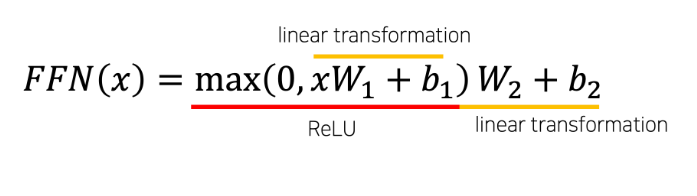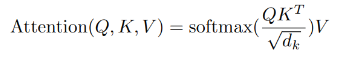강의 복습 내용
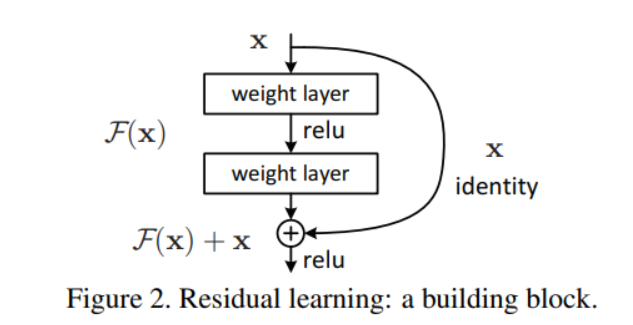
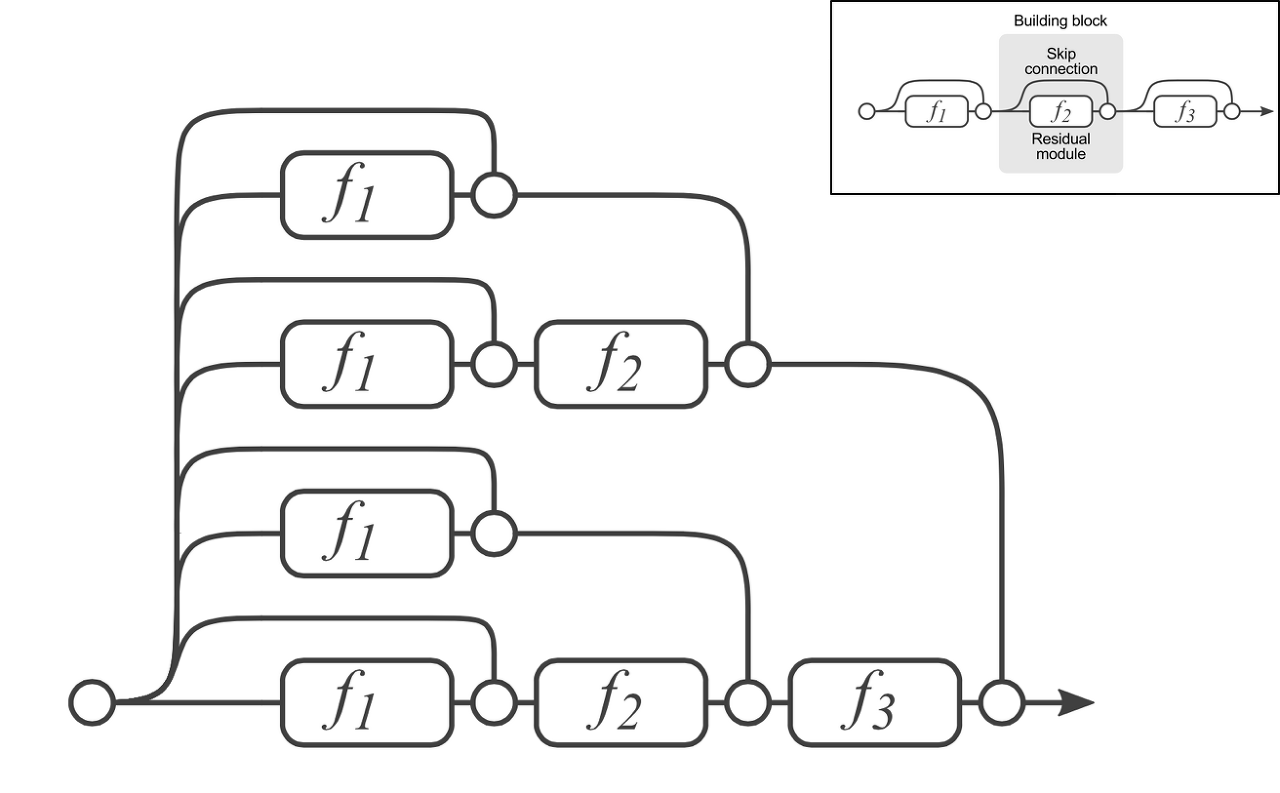
지난주 주말까지 해서 recsys강의를 마치고, nlp 도메인의 tranformer까지의 진도를 진행했다.
중간에 github특강으로 협업에대해서 공부하면서 다음주차에 예정된 대회를 준비하면서
지식을 가다듬는 한주를 보냈던 것 같다.
과제 수행 과정 / 결과물 정리
https://it-bejita.tistory.com/12?category=1044787
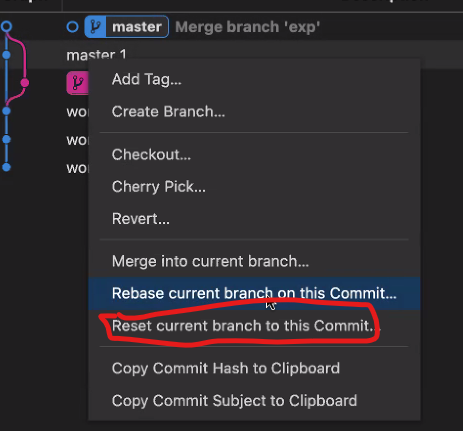
[부스트캠프] Github 특강 2회차
Tracked File이란? Unmodified/Modifed/Stage일 경우: 이 파일이 Git에 의해 관리가 되고 있다. Untracked일 경우: 이 파일은 Git에 의해 관리가 안되고 있다. (= 방금 추가한 파일이거나 쓸모없는 파일임을 추측..
it-bejita.tistory.com
https://it-bejita.tistory.com/13
[부스트캠프] Github 특강 3회차
conflict 관리 참고 영상 https://www.youtube.com/watch?v=wVUnsTsRQ3g git pull = fetch 와 merge를 한번에 해준다. 같은 이름의 branch여도 원격 저장소와 지역 저장소를 다른 브랜치로 취급한다. merge fast f..
it-bejita.tistory.com
피어세션 정리
Keep (잘한점)
- RecSys 강의를 빠르게 듣고 부족한 점 복습한 점
- nlp 강의 수강한 점
- 심화과제와 기본과제 충실히 수행한 것
- 스몰 토크로 친목 다짐
Problem(실수)
- github 특강 복습하기
- 시각화…
Try (계획)
- 건강 관리하기
- 프로젝트를 대비한 마음 비우기
학습 회고
5주차에는 github 특강으로 다음주차에 있을 대회를 준비하는 과정이었다.
그 과정에서 마음 속에는 어느새 조바심과 초조함이 자리했던 것 같다.
그 초조함과 조바심을 멘토님과의 멘토링 시간을 보내면서 현재에 집중하는 것의 중요성을 되뇌이며 성장했다.
지식을 순서에 맞게 쌓아가는 과정은 중요하다. 그리고 그보다 기초가 더 중요하다.
지금은 ML DL에 대한 기초를 쌓아가는 과정이다.
미래에대한 고민보다는 하루하루 묵묵히 할 일을 하는 것.
앞으로 남은 부스트캠프의 과정 뿐아니라 개발자로서 가슴 안에 새겨두기에는 좋은 마음가짐이라고 생각한다.
'부스트캠프 4기 RecSys' 카테고리의 다른 글
| [부스트캠프] 부스트캠프 첫 대회 회고 (0) | 2022.11.09 |
|---|---|
| [부스트캠프] window에서 AI STAGE 서버 SSH 연결하기 (0) | 2022.10.24 |
| [부스트캠프] Github 특강 3회차 (0) | 2022.10.21 |
| [부스트캠프] Github 특강 2회차 (0) | 2022.10.21 |
| [부스트캠프] 4주차 회고 (0) | 2022.10.14 |