def main():
n = int(input())
answer = [0] * 10001
for i in range(n):
answer[int(input())] +=1
#n ~ 천만이다. 메모리 터진다.
for i in range(10001):
if answer[i] != 0:
for j in range(answer[i]):
print(i)
if __name__ == "__main__":
main()
계속해서 시간초과가 발생해서 구글링을 해보았다.
for 반복문 안에서는 input 대신에 sys.stdin.readline()를 사용해서 시간초과가 발생하지 않는다고 한다.
input과 sys.stdin.readline()이 소모하는 시간 복잡도 값이 다르다는 사실을 알게 되었다..
어떻게 메모리를 더 줄이지 하는 고민으로 시간만 계속 잡아먹었다.
정답 코드
import sys
def main():
n = int(input())
answer = [0] * 10001
for i in range(n):
answer[int(sys.stdin.readline())] +=1
for i in range(10001):
if answer[i] != 0:
for j in range(answer[i]):
print(i)
if __name__ == "__main__":
main()
오늘의 회고
오늘이 다 끝나지는 않았고 이번주가 다 끝나지 않았지만 이르게 회고를 하고자한다.
이번주에는 회고할 내용이 많이 있지만 오늘은 많은 내용을 쓰지는 않을 예정이다.
7시에 끝이나고 술페션 피어세션을 하면서 다른 캠퍼분들과 많은 이야기를 할 수 있으면 좋겠다.
현재 팀원들과도 피어세션에서 발표도 진행하면서 각자 하고 있는 작업에 대해서 공유하는 시간이 좋았다.
또한, 서로 칭찬하는 시간을 가지면서 내가 인식하고 있는 나와 객관적인 나에대해서 인지할 수 있어서 좋았다.
이전에 풀었던 문항. 시험지가 다시 나오는 경우 -> 과거의 결과를 반영하면 성능 개선이 일어날 수 있을까?
-> 마스터 클래스에서 이전에 풀었던 문제에서 틀렸던 경우에도 모델에서는 다음에 풀었을 경우에 맞출 것이라고 예측한다고 한다. -> feature importance로 직접적으로 확인해볼 필요가 있을까?? 흠... FE에서 3옵션 정도로 남겨두자.
문항, 시험지, 태그의 평균 정답률
문항, 시험지, 태그의 등장한 횟수가 정답률과 어느 정도 상관 관계가 있다.
Data Leakage
train, test 데이터가 분리되어 있기 때문에 이를 고려해야한다.
train과 test에서 성능의 차이를 줄이기 위한 방법 중 하나는 역시 데이터를 늘리는 것이다.
다양한 방법으로 고유한 Feature 추출하기
Matrix Factorization
사용자와 사용자가 푼 문항을 통해 user-item 행렬을 만들어줄 수 있다.
-> 실제로 대회에서 제공해준 lightGCN 같은 경우에 테스트 데이터에서 맞춰야 되는 값의 이전 데이터를 사용해서 MF를 만들어준다. => 이렇게 만들어진 MF 를 임베딩 할 수 있는 Feature로 쓸 수 있는 모델과 다른 모델에 어떻게 임베딩해서 적용할 수 있는지 고민해 볼 여지가 있을 것 같다.
유사한 방법으로는 SVD가 있다.단, svd의 단점은 빈공간이 다 차있어야한다. 물론 0으로 fillna를 해주겠지만...
ELO
ELO,IRT를 활용할 수 있다. -> 학생의 잠재능력을 가정하고 학생의 과거 데이터를 토대로 모수를 추론-> 문제의 난이도, 정답률을 보고 이 둘의 관계를 계산해서 정답률을 추론한다.
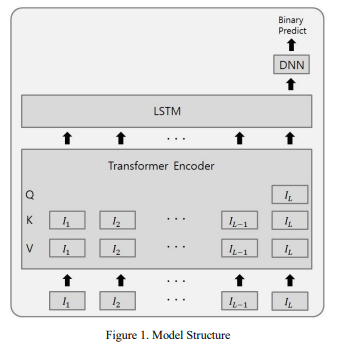
1. 다수의 feature를 사용 안하고 Sequence를 늘렸다. -> 시간 복잡도가 상승함
2. 마지막 Query만 사용하여 시간 복잡도를 낮췄다.
3. 문제 간 특징을 Transformer로 파악,
일련의 Sequence 사이 특징들을 LSTM을 활용해 뽑아낸 뒤 마디작에 DNN 을 통해 Sequence 별 정답을 예측함
+) 개인적으로는 FE를 transformer로 대체하고, 그 대신 늘어난 시간 복잡도는 마지막 query만 사용하면서 FE에 시간 투자도 안해도 되고, 모델을 돌렸을 때의 시간 소모도 줄이면서 sequence 형태로 데이터를 소모하는 좋은 모델로 보인다.
+) 위 모델을 구현해본 사람이 첨부해둔 Git 주소를 발견하였다. 하지만 이전에 Tabnet 구조를 만들어둔 사람의 git을 참고해서 이식해보려고했지만 실패했던 경험이 있어서 두렵기는 하다. 라이브러리화 되서 제공되는 모델들은 사용하기 쉽지만 이렇게 git으로 구현되어있는 모델들을 활용해서 data에 맞게 돌리는 것은 조금 더 난이도가 높은 듯 보인다.
def main():
s = int(input())
#3 5
m_3 = int(s/3)
l_3 = s%3
m_5 = int(s/5)
l_5 = s%5
answer = 99999
#
if l_5 ==0:
return print(m_5)
else:
for i in range(0,m_5+1):
for j in range(0,m_3+1):
if i*5 + j*3 > s:
break
if i*5 + j*3 == s:
answer = min(answer, i+j)
if answer == 99999:
return print("-1")
else:
return print(answer)
그냥 빡구현 어거지로 풀었다.
그래서 모범적인 풀이는 무엇일지 검색해보았다.
sugar = int(input())
bag = 0
while sugar >= 0 :
if sugar % 5 == 0 : # 5의 배수이면
bag += (sugar // 5) # 5로 나눈 몫을 구해야 정수가 됨
print(bag)
break
sugar -= 3
bag += 1 # 5의 배수가 될 때까지 설탕-3, 봉지+1
else :
print(-1)
while ~ else 조건문을 사용해서 break에 걸려서 나가지 않으면 자동적으로 -1을 출력해준다.
내가 짠 코드는 거의 완전 탐색에 가까운 방식이어서 시간 복잡도가 조금이라도 타이트했으면 바로 오류가 났을 것 같다.
오늘의 회고
오늘로 DKT 대회 4일차이자 LG AI Ground를 본격적으로 시작한 첫날이다.
DKT 대회에서 주어진 베이스라인 코드들을 기억해두고 나중에 적용할 수 있을 만큼 학습하는 것이 dkt에서의 또하나의 목표라고 생각이든다. 부스트캠프 과정에서 얻을 수 있는 가장 대표적인 교육 과정이며 가져가야 할 것이다.
매일매일 알고리즘 문제를 1문제씩 푸는 것은 계속해서 이어나가야할 생활 습관이라고 생각이 든다. 이제 겨우 3일 정도 된 것 같은데 간단하게 문제를 푸는 정도라면 스트레스도 풀리고, 내가 성장하고 있나 하는 불안감 해소에도 도움이 된다.
AI ground 팀과 첫 미팅을 하면서 느낀 점은 목표를 향해 나아갈 때는 동료와 함께 달려가는 것이 좋다는 점이다. 무엇보다 서로 의견을 교류하면서 동기부여도 되고, 같이 하고 있는 팀에대한 책임감으로 task에 대한 집중도가 올라가는 것을 느낀다. DKT, book rating에서도 EDA를 진득하게 해본 적은 없는 것 같다. DKT를 하면서 어느정도 eda를 해보았지만 특정 column을 분석하면서 아이디어를 얻은 후 top-down으로 FE를 해본 것이기 때문에 이번에는 bottom-up 을 할 수 있을 정도로 EDA를 진행해보자.
부스트캠프를 진행하면서 너무나 좋은 사람들을 너무 많이 만나고있다. 그런데 주변 사람들이 이 힘든 과정 속에서 힘들어하는 모습들이 보이고 있다. 동료들이 힘들어할 때 웃음을 줄 수 있는 사람이 되자. 다들 이렇게 힘들어하고만 있기에는 너무나 뛰어난 사람들이기 때문에 내가 할 수 있는 최선을 다하며 주변에 에너지를 주는 사람이 되자. 지금 이 과정이 육체적으로는 힘들 수 있지만 언제나 말하듯이 내가 할 수있는 최선의 방법은 너무나도 간단하다. 나 스스로는 최선을 다하며, 주변의 사람들에게 먼저 인사하며 잠시라도 웃을 수 있게 열심히 하자.
lightGCN - MF 계열인 것처럼 보인다. 먼저 interaction 을 만든 후에 예측한다.
DKT - Sequential 데이터를 다루는 것이 특징이다. sequential한 feature를 추가할 수 있는 방향으로 고민해볼 것
EDA
Timestamp 에서 확인하고 싶은거
1)시간이 지나면서 성장하는 애인가, 물로켓인가 검증(초반에 좋았던게 럭키이고 공부할수록 못하는 케이스)
a) 아직까지는 userID로 groupby한 후에 학습률과 정답률을 비교하는 것으로 하려고 했지만 아직까지는 확인하지 못했음
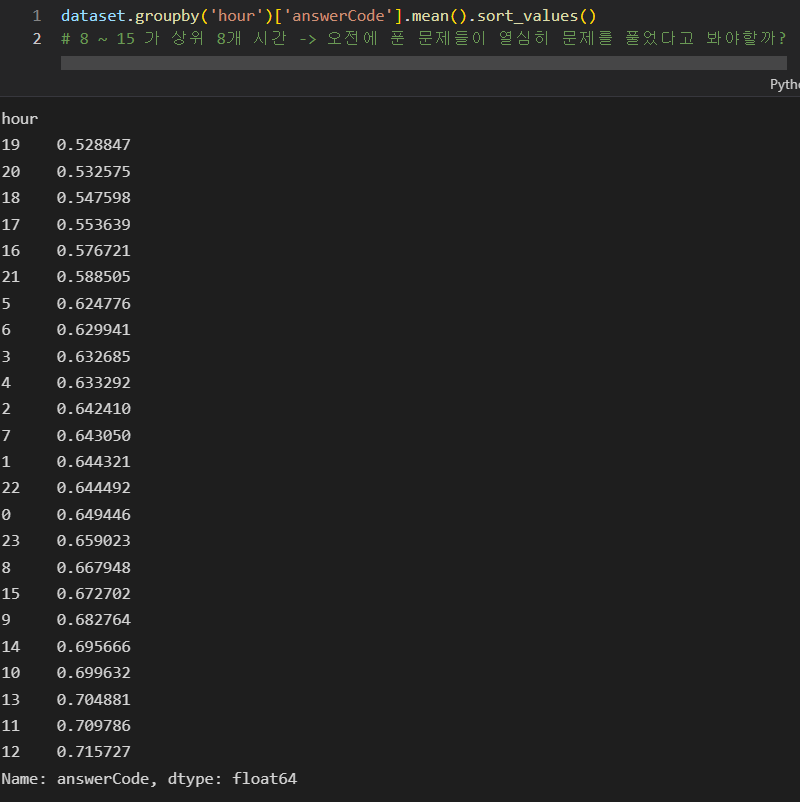
2)밥 먹고나면 졸려서 문제를 못 푸는 경우가 있나? , 특정 시간에서 잘하는지 확인하고 싶음
a) 처음에는 밥 먹고나면 문제를 잘 못풀거라고 생각했는데 전혀 틀렸다.
아래와 같이 8~15시에 문제를 풀었던 것의 정답률이 상위권을 차지했다. 그냥 오전에 공부할 때 풀었던 사람들의 문제가 정답률이 높았다고 생각하는 것이 좋을 듯 하다.
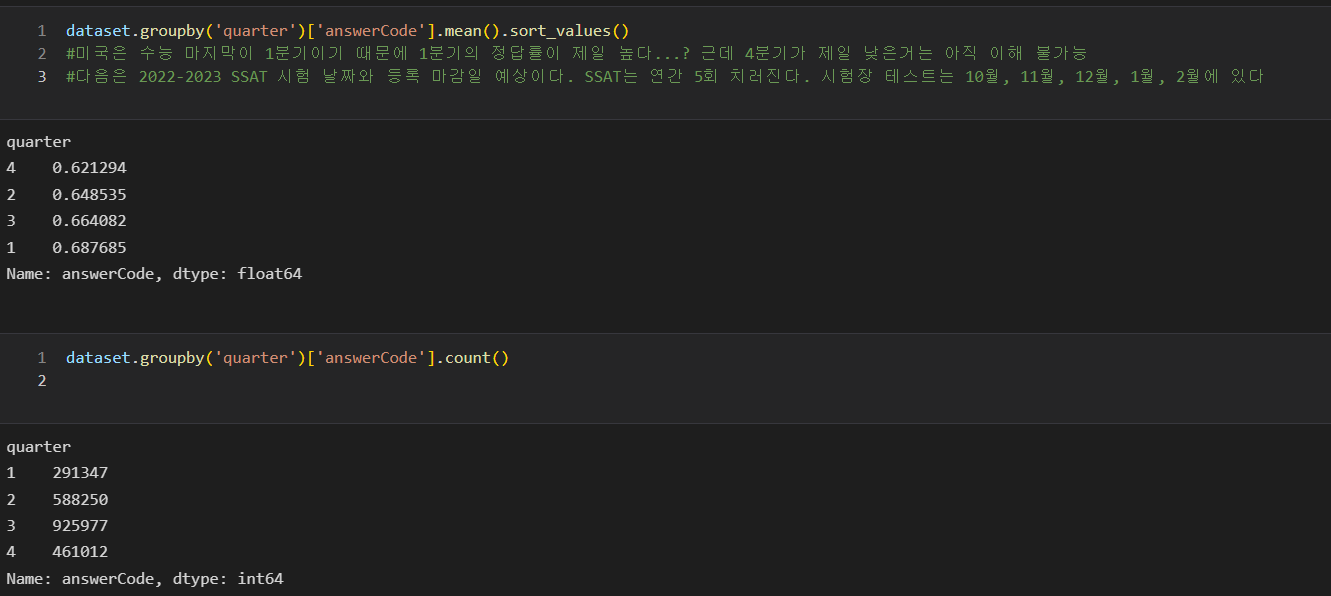
3)우리나라의 경우 연말이 가까워질수록 (수능이 가까워질 수록 학생들의 학습률이 올라가면서 정답률이 올라가지 않을까?)
a) 이것은 마스터 클래스에 데이터 도메인이 초등 수학 문제 풀이라는 것을 알기전에 추론했던 영역이었다.
하지만 초등 수학문제라는 것을 알게 된 후에는 내가 너무 삽질을 했구나... 하는 생각을 했다.
위 처럼 1분기에 정답률이 높길래 설마 미국 데이터라서 ssat가 이루어지는 것과 연관성이 있나? 했지만
연관성이 우연의 일치로 1분기가 높았다고 생각이 든다.
하지만 팀원이 month로 다시해서 보면 어느정도의 편향을 예측할 수 있을 것 같다고 말해주어서
내일 달 별로 확인해보고 결과를 확인하고자 한다.
+)
어제와 오늘 진행했던 EDA로 Feature를 저장해서 기존의 모델에 돌려보면서 리더보드와 validation에서 어떻게 성능이 개선되는지를 확인해보고자 했다.
우선 Timestamp를 가지고 생성했던 feature를 사용해서 베이스라인에는 아직 적용을 하지 못했지만 어느정도 성능개선이 있었다.
내가 생각했던 것 보다 이렇게 성능이 많이 오를 수 있나 싶을 정도로 개선이 되어서 놀라웠지만 EDA를 통해서 Feature를 만들고 이를 모델에 적용해보면서 생각이 틀렸는지 아닌지를 점검해보는 방식은 이전에 수업을 학습하면서 배우는 것보다 더 능동적이고 재미있는 것같다.
그전에 check를 하고 전체를 돌리는 방식으로 코드를 의식의 흐름대로 짜다보니 당연하게도 시간초과가 나왔다.
이 과정에서 hard copy를 위해서 deepcopy()도 사용했다. 일단 여기서 시간 터짐. 반성하자
import copy
copy.deepcopy()
n*m 번을 무지성으로 서치하는 것이 아니라 그 과정에서 deque 사용해서 리스트로 넣고 그 리스트에 들어간 애들을 따로 돌리는 방식의 정형화된 bfd로 수정하고나서야 시간초과가 해결했다.
일단 무지성으로 코드를 짜보는 것도 도움이 되기는한다. -> 일단 빡구현실력은 개선 될 수 있다고 봄
하지만 어느정도 bfs,dfs 라는 감이 잡혔으면 deque 사용해서 시간을 최소화하는 방식을 자연히 무지성으로 짤 수 있을 정도로 루틴화 되어야 할 것 같다.
+) 확실히 골드와 실버부터는 시간초과를 신경을 많이 써야 한다. 앞으로도 배울 점이 많고 재미있는 과제들이 너무나 많다. 힘내자
오늘의 회고
오늘로 DKT 대회 3일차이다.
이번 대회에서는 학습하며 배우는 것도 하고 싶었지만 이전 대회에서는 모델을 추가하는 것에 급급해서 아쉬웠던 점을 보완하고 싶었다. 그래서 EDA 부터 FE 그리고 모델에 테스트 해보고 난 후에 Validation이랑 어느정도 연관이 되는지를 확인해 보고싶었다. 위의 과정에서 validation을 어떻게 만들지에대한 고민을 더 해봐야 겠지만 아직까지는 그것에 대한 insight는 얻지 못했다. 이를 위해서 많은 사람들과 어떻게 하면 좋은 validation을 얻을 수 있을지 대화하고 싶다.
우선 처음으로 시도했던 실험이 생각보다 성능이 개선되어서 0.8을 넘길 수 있었다. 이것도 팀원이 도움이 있었기에 실험의 결과물을 리더보드 결과물로 연결해서 성과를 맛 볼 수 있었던 것 같다. 정말이지 좋은 팀원들과 상호작용을 하며 성장하는 것은 무엇보다 강한 동기 부여가 된다. 개인적으로는 피어세션 시간에 내가 생각하고 실험했던 내용을 어떻게하면 조금 더 잘 설명 할 수 있을지 고민해봐야 겠다.
아쉽게도 이렇게 DKT에 집중하고 있는 동안 AI Ground에는 집중을 많이 하지 못했던 상황이라 내일 있을 AI Ground 대회 팀과의 회의에서 조금 더 잘 할 수 있도록 내일은 저녁 먹고 난 이후부터 EDA 와 기초 모델링을 실험부터 시작해야 할 것 같다.
오늘 부캠 라디오를 들으면서 사람들도 오프라인 회식을 원하는 모습이 있었던 것 같다. 이전 기수 방식 중에서 2주 마다 사람들이 제일 많이 모일 수 있는 곳으로 선정해서 결정을 했다고 하는데 이 방식은 아무거나 톡방에서 스페셜 피어세션을 결정할 때 적용하면 좋을 것 같다. 물론 12월 달에 이종혁 멘토님이 오프라인 회식 채널을 만들어 준다고 하셨으니 기대하고 있다.