DKT 강의 3~4강 학습
Sequential Data 의 차이점
본 대회에서는 시간에 따라서 문제를 풀기 때문에 시간, 순서의 요소가 있다.
+) 시간이 지나면서 성장하는 애인가, 물로켓인가 검증
집계(Aggregation), Feature Engineering
→ 유저의 다양한 정보를 하나로 합치는 과정에서 데이터 손실이 일어난다.
transaction 그래도 사용 + Feature Engineering
타임스탬프를 요일로 나눈다거나, 특정 시간에 집중을 잘한다거나
+) 밥 먹고나면 졸려서 문제를 잘 못푼다거나 , 특정 시간에서 잘하는지 확인하고 싶음
- Make ground baseline with no fe
- Make a small FE and see I you can understand data you have
- Find good CV strategy(Custom Validation)
- Feature selection
- Make deeper FE
- Tune Model (crude tuning)
- Try other Models (never forget about NN)
- Try Blending/Stackin/Ensembling
- Final tuning
Konstantin Yakovlev, How all works together https://www.kaggle.com/c/ieee-fraud-detection/discussion/107697
+) 3. custom validation 과 리더보드가 같이 올라가고 내려가는 지 확인
4.feature 하나씩 실험해 보면서 선택한다.
8.할거없으면 Seed 앙상블
대회에서 어떻게 하면 같이 일을 할 수 있는지 알려주는 리스트이다.
이번 대회에서 참고하면 좋을 듯 하여 블로그에 포스팅 하고자 한다.
Transformer가 Sequence에 유리한 이유
1)Sequence 안에서 모든 token이 다른 token을 참조한다.
2)Positional Embedding을 추가하여, Sequence 내에서 위치 정보까지 반영할 수 있다.
Feature Engineering
Timestamp 에서 feature를 추출할 수 있는 변수들을 모두 추출
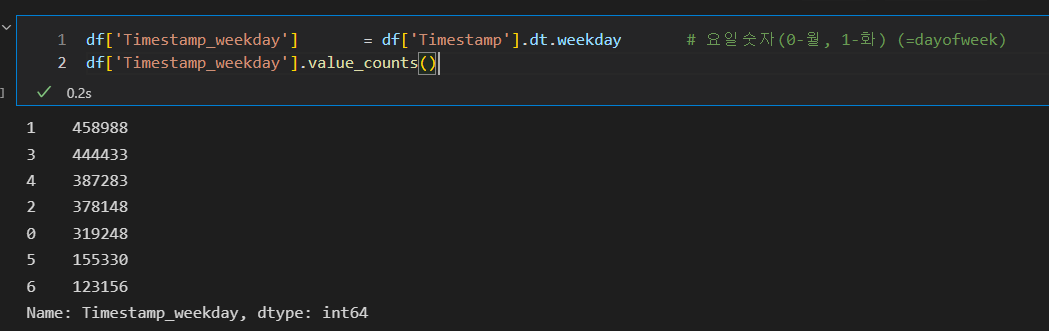
- Timestamp_weekday
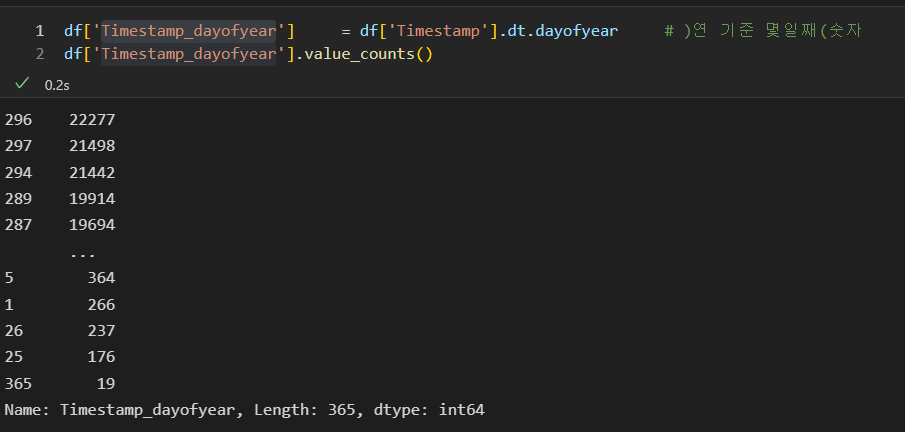
- Timestamp_dayofyear
- Timestamp_week
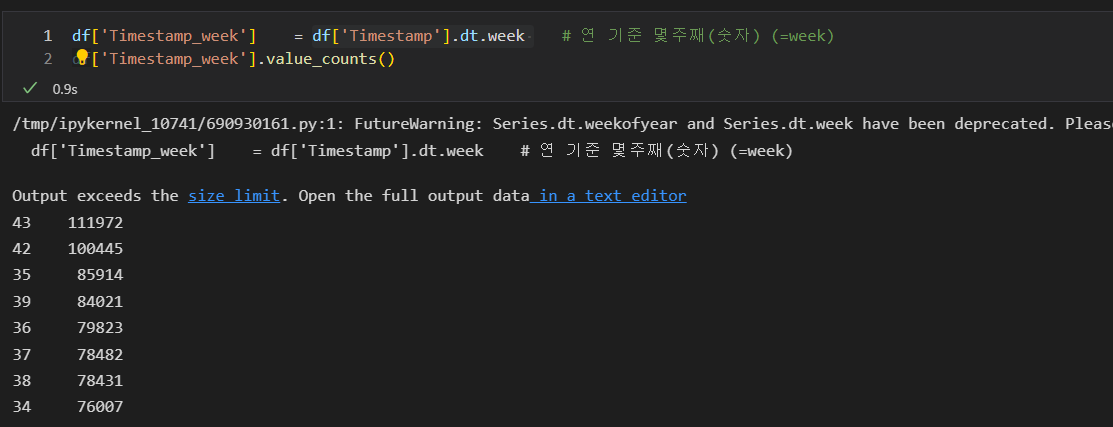
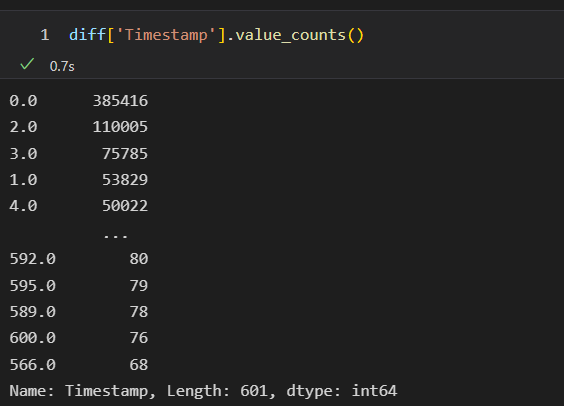
- solve_time
- 아래와 같이 다음 시간과의 차를 통해서 시간을 구했지만 다음날 문제를 풀면서 터무늬없는 값이 계산되는 경우가 있다. -> 600초 이상은 0으로 바꾸어준다.
이렇게 문제 푸는 시간이나 요일 시간 등을 feature로 만들었지만 DKT, light gcn 에서 어떻게 사용하게 만들지는 아직 확인하지 못했다.
따라서 이를 해결하기 위해서 baseline 분석과 feature 엔지니어링을 같이 확인하여야 할 것 같다.
알고리즘 문제 풀이
- 개인 깃허브 알고리즘 코드 링크 https://github.com/SeongJaeBae/algorithm
오늘은 머리가 복잡해서 그냥 solved.ac 에서 제공되는 클래스 1 단계 bronze 난이도의 문제들을 빠르게 풀면서 스트레스를 풀었다. 1시간 정도 하고 난 후 확인해보니 14 문제 정도 풀었다.
+) 추가로 한 일
aistage 팀 마크 세팅
git project, issue 사용해서 팀원들간에 협업하기
오늘의 회고
오늘은 아무래도 강의에 완전히 집중을 하지 못하고 이것저것하다가 하루를 보냈던 것 같다.
그러다보니 먼가 마음이 허해서 되도않는 쉬운 알고리즘 문제들을 풀면서 스트레스를 풀려고 했지만... 그냥 너무 쉬운 문
제들이라 단순 코딩 작업일 뿐이었지만... 하루하루 포기하지 않고 해나가고 있다는 것에 만족하자.
오늘은 '아무거나' 채널에서 처음으로 스페셜 피어세션을 하게 되었는데 다행히 CV 캠퍼분이 참석해주셔서 정말 고마웠다. 앞으로도 계속해서 서로에게 좋은 피드백을 줄 수 있도록 RecSys 분야를 제대로 학습해야겠다.
내일은 우선 강의를 끝까지 듣고 베이스라인을 분석해서 dkt, lightgcn 두 모델 모두 feature를 추가로 넣었을 때 효과가 있는지 또한 코드로 적용하는 것도 확인해보고자 한다.
내일 할 일을 오늘 조금 정리하면서 하루를 마치면 내일은 조금 더 알차게 일을 할 수 있을 것 같아서 괜히 기대가 된다.
내일 우.팀.소 발표도 예정되어 있는데 점심을 먹으면서 연습을 해야겠다.
또한 LG AI GROUND 대획도 팀을 결정하게 되어서 하루에 1~2시간 씩이라도 집중해서 베이스라인 분석과 EDA를 해야겠다. 사실상 12월 2일까지 2주 반 정도 남은 상황이기 때문에 주말과 7시 이후에 집중적으로 할수 있는 모든 시도를 해봐야겠다.
'부스트캠프 4기 RecSys' 카테고리의 다른 글
| [부스트캠프] DKT 4일차 (3) | 2022.11.18 |
|---|---|
| [부스트캠프] DKT 3일차 (2) | 2022.11.17 |
| [부스트캠프] DKT 1일차 (0) | 2022.11.14 |
| [부스트캠프] 8주차 회고 (0) | 2022.11.11 |
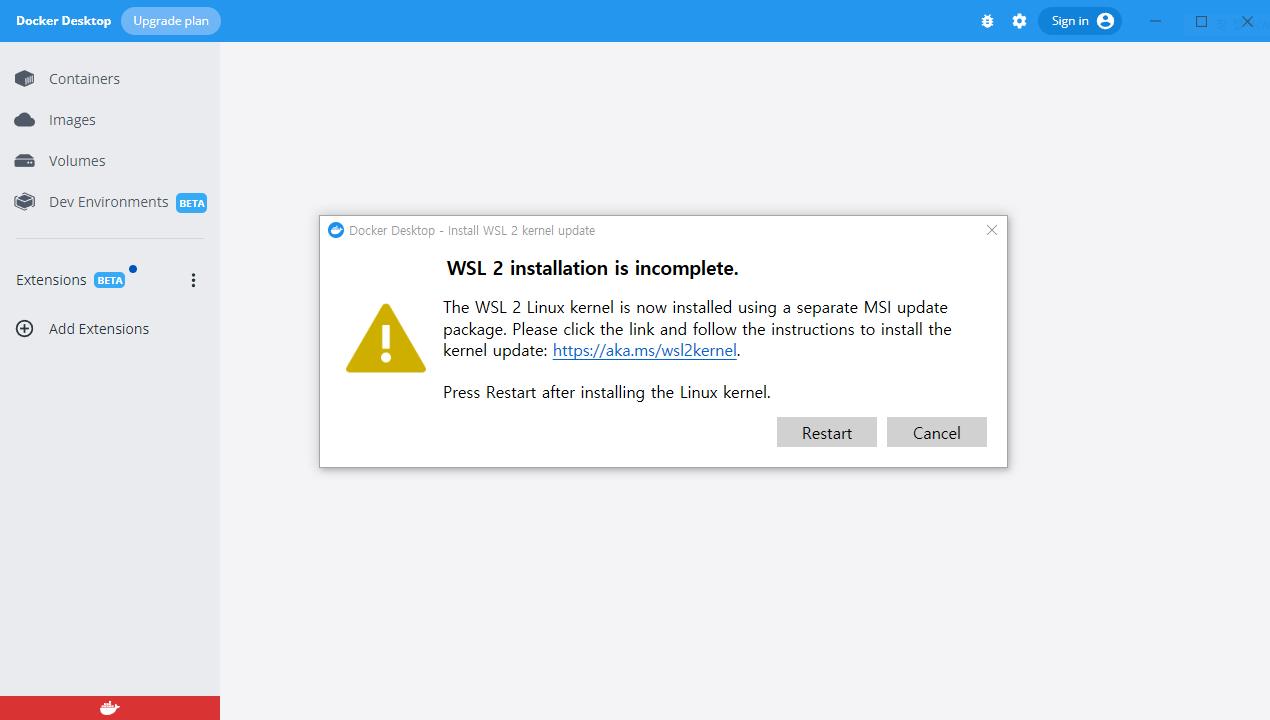
| [window 10 Home] docker 설치 에러 Hardware assisted virtualization and data execution protection must be enabled in the BIOS. (0) | 2022.11.10 |